I decided to continue my journey with Kaggle and different datasets there, and to combine it with learning something new. While I used to check there some neutral datasets, and disappointed myself again with the inability to compose correct ML techniques on competitions, I still like to check what I can do with video games datasets, or try to extract some gaming-related stuff in common data sources.
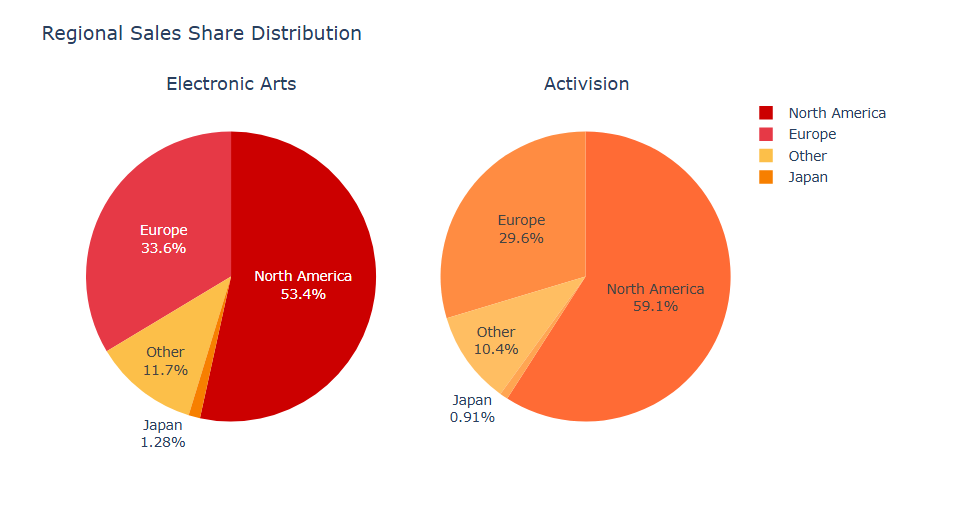
Electronic Arts vs Activision
URL: https://www.kaggle.com/code/lunthu/electronic-arts-vs-activision-publishers-rivalry
In this notebook (based on VGChartz data) I decided to check the history of rivalry of the biggest third-party video game publishers, which are commonly attributed as “worst-evil corporations, constantly fighting against creativity & gamers”. It’s hard to argue that both Activision and Electronic Arts have a controversial journey, but they still contributed a lot in what we currently name as a video games industry. So, in this notebook I tried to check what was common and different during their history.
In this notebook I mostly focused on Plotly visualization – it makes overall observation too descriptive sometimes, buuut, I still like it!

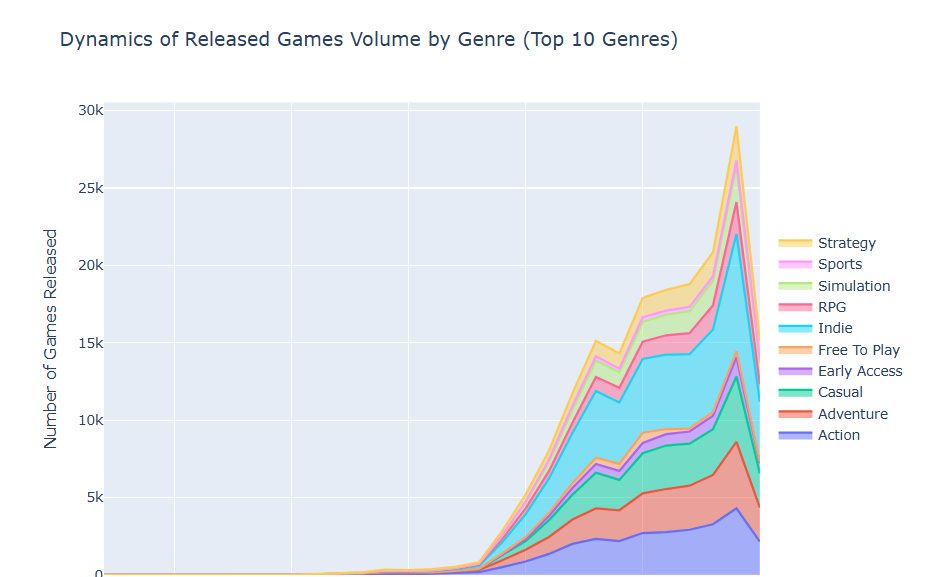
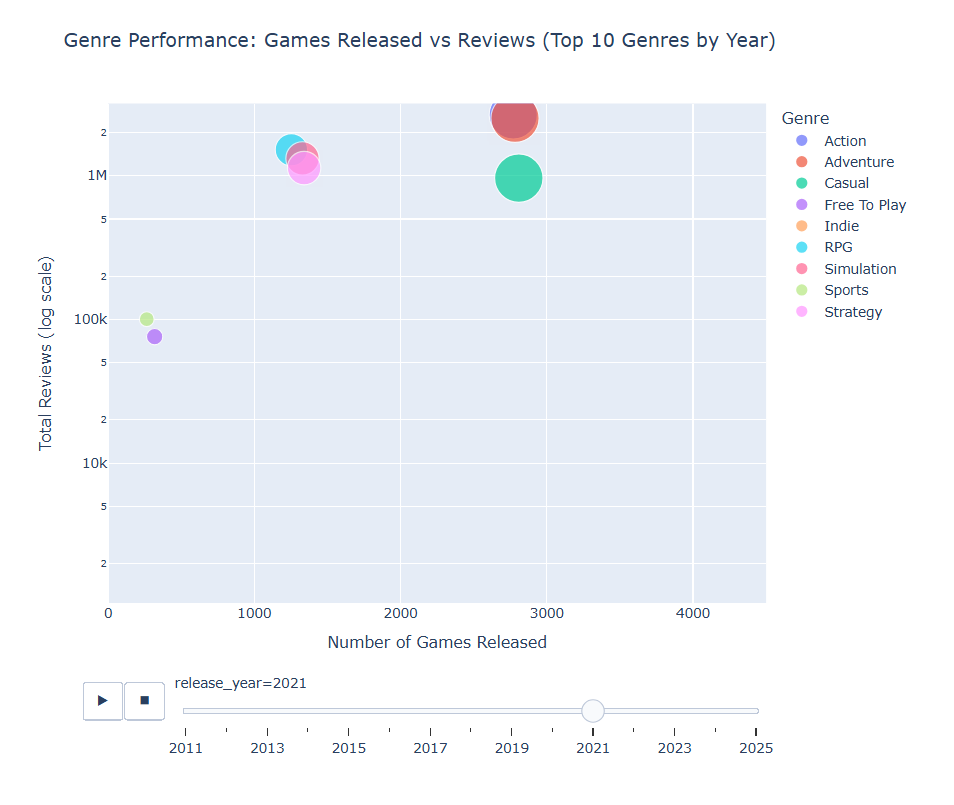
Steam Genre Trends
URL: https://www.kaggle.com/code/lunthu/steam-genre-trends-pyspark-plotly
This notebook is my very first attempt to do something with PySpark on Kaggle – and I liked it! I will try to speak about PySpark somewhere in the future, but in this dataset I decided to try it just due to the size of original data source (~1 GB) – and to check genre dynamics in Steam year-over-year. This notebook also can be named as too descriptive, but my goal was more to check something instead of Pandas. Also, this time I’ve tried to make a dynamic scatter plot – I never thought it could be so funny!
Wikipedia Video Game Articles
URL: https://www.kaggle.com/code/lunthu/wikipedia-video-games-pyspark-graph-analysis
My current most ambitious thing on Kaggle – an attempt to parse all Wikipedia content (100+ GB, PySpark in this case is necessary as never – in other cases one notebook sprocessing can take days), to extract video-game-related content and to build some dataviz about it.
One challenging part here was related to complexity of original dataset – it is a set of JSONL files with nested structures inside of nested structures – which is also different from one case to another.
Another challenging thing that currently still needs to be optimized – how exactly extract articles about video games. Articles in dataset are not labeled, and metadata about tags is also not presented. So, I decided just to extract something based on key words – but it caused even more funny situations. For example, in initial keywords set I had “rpg” and “fps” terms – which added a lot of medical and military-related articles. Also for some reason I’ve added there word “steam” – and collected everything about trains of 19th century.
For visualization part I decided to play with graph analysis, and used pyvis – I still not sure about its accuracy, but looks ambitious!