
Need to mention one more fact about myself – I really like computer games. I cannot say that I have enough time to spend with this hobby, but I still continue monitoring this industry and also intact with major platforms responsible for video games distribution.
And one more fact about me – sometimes I like to investigate if any such platform has an option somehow to extract data, either by API or by other more or less legal methods.
Today I decided to pay attention to GOG.com, one of the most noticeable PC gaming-related video games platform, focused on video games preservation and indie gaming support. In this article I will try to show how to extract data from GOG (basic stats about video games on platform and reviews data), and to discuss on how it can be used.
GOG.com has relatively good API services, described here: https://gogapidocs.readthedocs.io/en/latest/. Need to say that some of methods seems to be outdated and in some cases not everything is documented – but it should be not a showstopper for us, right?
Games data
Basic video games data can be extracted with Listing-related methods presented here: https://gogapidocs.readthedocs.io/en/latest/listing.html. The key component of that journey should be to make requests via “embed.gog.com” host with page path “/games/ajax/filtered?mediaType=game”. As a response, this request returns dict-like result, which later will be relatively easy parsed by json.loads function.

What is interesting, these methods do not require any access tokens, sending of any user data, or any other ways of authentication – potentially it can be fixed in future.
Due to that, from the perspective of Python code, for us it will be enough to have:
- requests library – for making of GET request
- json library – for parsing of dict-like
- pandas – for transforming of list of dicts to DataFrame
A basic code with request should be the next:
import requests
import json
import pandas as pd
basic_request = requests.get('https://embed.gog.com/games/ajax/filtered?mediaType=game'.format(i))
basic_request_json_data = json.loads(basic_request.text)An output:
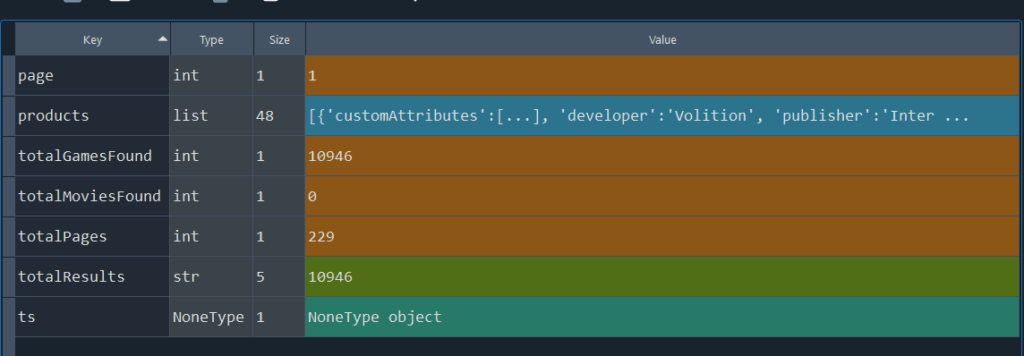
Two items which should be out point of interests, are objects products – it contains 48 items with information about selected games, and totalPages – it contains number of iterations needed to extract all video games data from selected sample.
Pages switching activity is not presented in unofficial API documentation, but on https://www.gogdb.org/moreinfo it is mentioned that it easily can be done with addition of GET parameter “&page=” to initial request. Due to that, in case we want to extract the whole dataset and already transform it to pandas DataFrame, the next code should work:
import requests
import json
import pandas as pd
import time
df = pd.DataFrame()
pages = 229
for i in range(1, pages):
basic_request = requests.get('https://embed.gog.com/games/ajax/filtered?mediaType=game&page={}'.format(i))
raw_data = pd.DataFrame(json.loads(basic_request.text)['products'])
df = pd.concat([df, raw_data], ignore_index = True)
time.sleep(0.33)
price_data = pd.json_normalize(df['price'])
df = df.join(price_data, lsuffix = "_main")
df = df.drop(['price'], axis = 1)Need to point an attention on the next things:
- This code can be done in a significantly more flexible way – I used static value for pages, but instead of that it can be extracted with the first request.
- For each iteration of for-cycle I added time.sleep for 0.33 to avoid overload of API – I didn’t find it as a necessary step in API documentation, but added it just in case
- I’ve extracted to separate columns data from ‘price’ array due to easier interaction with price-related items in final table.
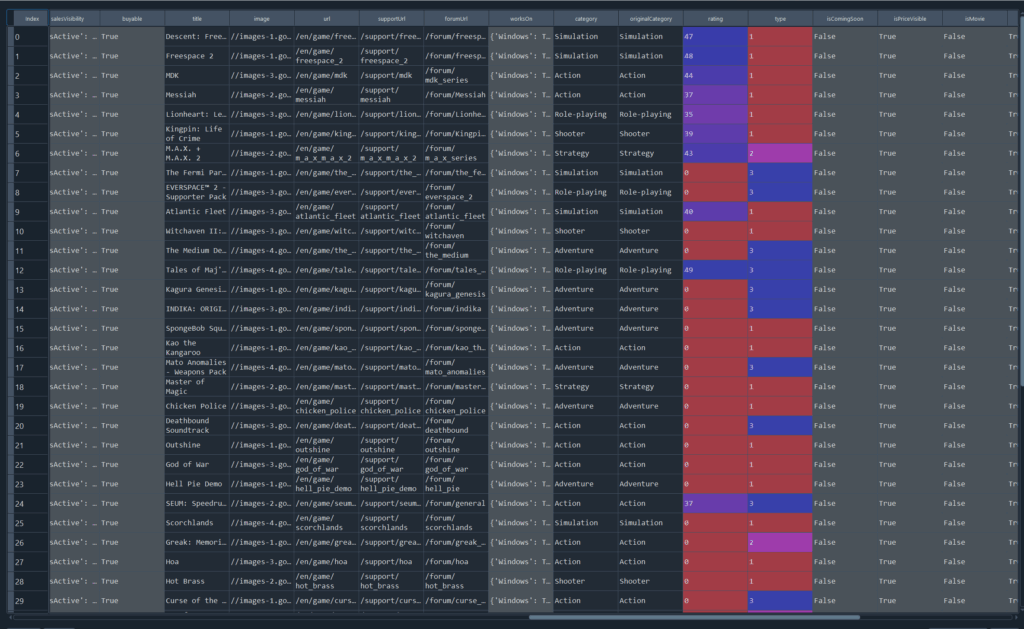
Reviews data
Basic request is not containing one potentially very interesting part of GOG.com data – reviews volume for each game. Since sales data is not accessible, such metric could be helpful for indirect understanding of popular/successful games, and, potentially, reveal some trends on more or less successful genres, series and developers.
Unofficial GOG API call for reviews https://gogapidocs.readthedocs.io/en/latest/reviews.html didn’t work for me unfortunately – in all cases related queries presented me empty list. Due to that, I went to the website by myself and checked what is firing in Network section in DevTools when I’m on random video game page. There, I had a chance to find method named as reviews.gog.com/v1/products/{id}/reviews, which already contains everything necessary!
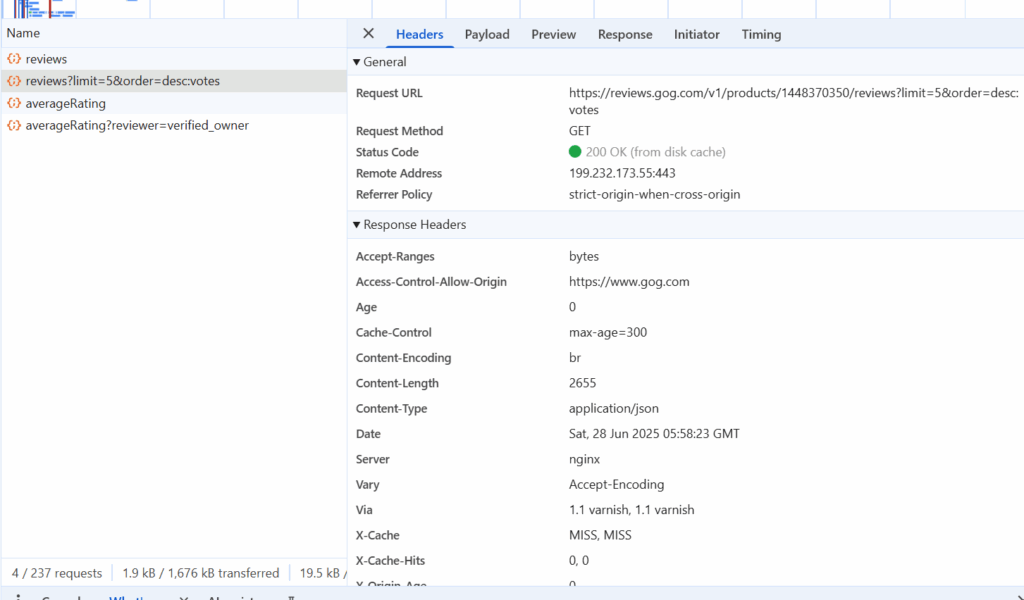
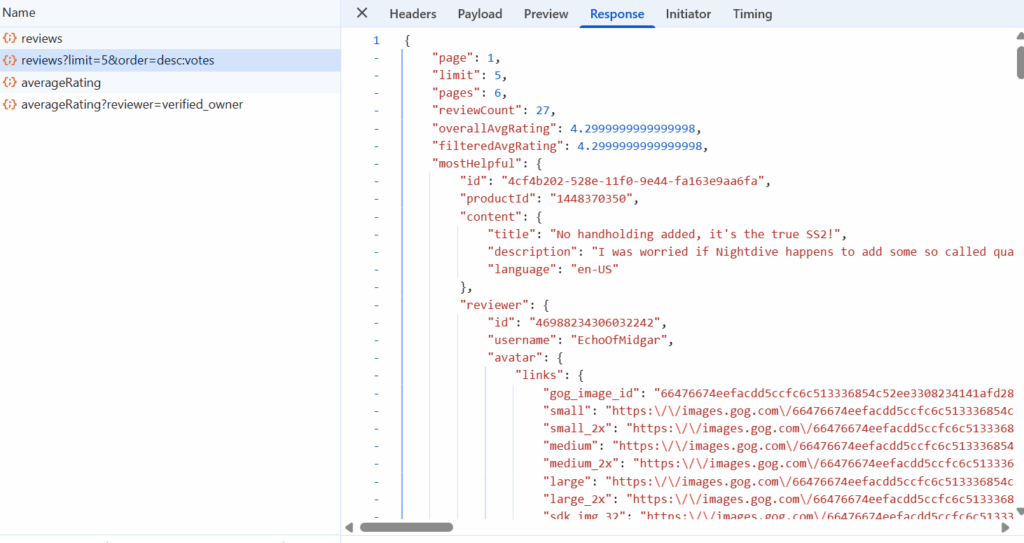
One response contains the next items:
- Aggregated data about reviews count and avg rating globally and for selected sample.
- Information about the most helpful review.
- 10 reviews located in _embedded dict object. This count can be increased to 60 items per request by “&limit=” GET parameter.
- Switching between pages works with “&page-” GET parameter.
- As for video games stats, request is not requiring any access tokens.
In this post, I’m not so interested in reviews content, my goal is to extract reviews volume count for each game together with average ratings. It will require to make one requests for each of 10k games in GOG library. I did it in the next way:
def reviews_agg_data(game_id):
aggregated_data = {}
basic_request = requests.get('https://reviews.gog.com/v1/products/{}/reviews?language=in:en-US&order=desc:votes'.format(game_id))
buf = json.loads(basic_request.text)
aggregated_data['game_id'] = game_id
aggregated_data['filteredAvgRating'] = buf['filteredAvgRating']
aggregated_data['overallAvgRating'] = buf['overallAvgRating']
aggregated_data['reviewCount'] = buf['reviewCount']
aggregated_data['isReviewable'] = buf['isReviewable']
aggregated_data['pages'] = buf['pages']
pages = buf['pages']
return aggregated_data
reviews_agg_storage = []
ids_list = df['id']
for i in ids_list:
agg_data = reviews_agg_data(i)
reviews_agg_storage.append(agg_data)
df_reviews = df(agg_data)In this code I do the next things:
- Initiate a function which makes a request to selected game and extracts aggregated reviews data in dct format.
- Extract list of game ids from our previous request.
- In for-cycle – call reviews_agg_data function for each game with appending it to list – so we will have a list of dict objects
- Transform it to DataFrame.
On the very last step, we need to unite that data with our original table – I did it by simple join by indexes:
df = df.set_index('id')
df_reviews = df_reviews.set_index('game_id')
df = df.join(df_reviews)You are amazing!

What’s next?
So, we have a dataset with video games presented in GOG, which includes some basic data about developer, published, genre, release date, price and reviews volume. It already creates some space for further analysis – for example, to check correlation between reviews volume and price, or to check which genres are more popular.
At this point of time I just made a simple Power BI dashboard for some initial EDA – but, of course, this activity can be significantly expanded. For example, for me it was a big surprise to see that Mafia has more reviews than Witcher 3! Or that fact that Heroes of Might & Magic 4 is in top-30 by reviews.
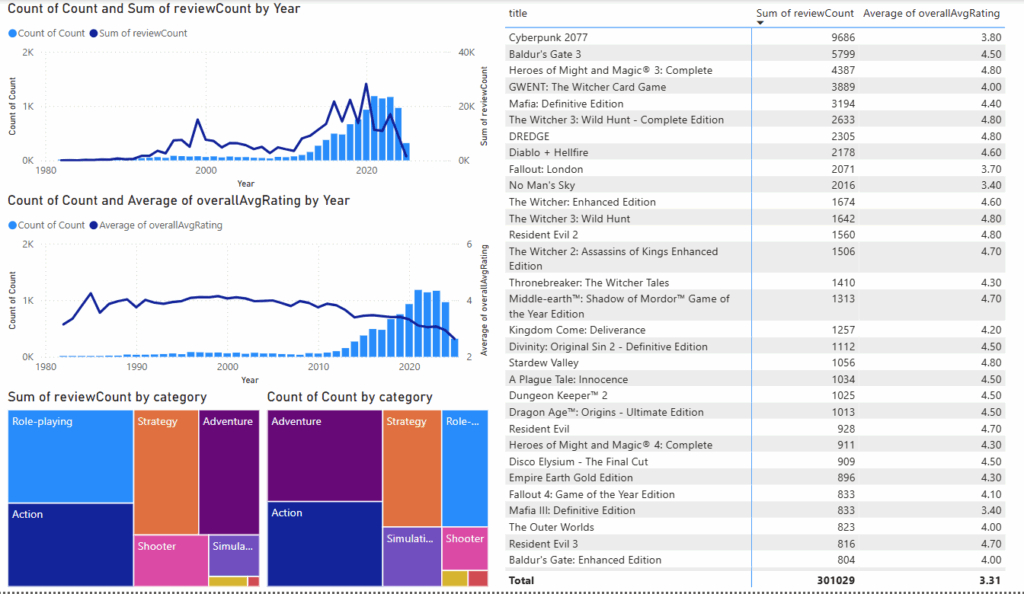
I also would place here a link to github with functions and extracted datasets – functions and variables names there are a bit different than in this article, but the overall logic is saved: https://github.com/Lunthu/gog-analyze
Please let me know what do you think on that in my LinkedIn: https://www.linkedin.com/in/victor-laputsky-44199bab/